

Full Source Code released: on GitHub
!IMPORTANT NOTE: Mass Site Visitor’s support is discontinued. If you ever intend to use it – you’ll have to figure how to configure and set it up and update drivers yourself by following the pdf manual. Source code of MSV: on GitHub
!IMPORTANT NOTE: Mass Site Visitor is sold exclusively on Envato (Codecanyon) since 2016 (I also used to sell it at SeoClerks/Codeclerks as headshote, but these marketplaces are dead now), anybody else trying to sell this bot to you is a scammer
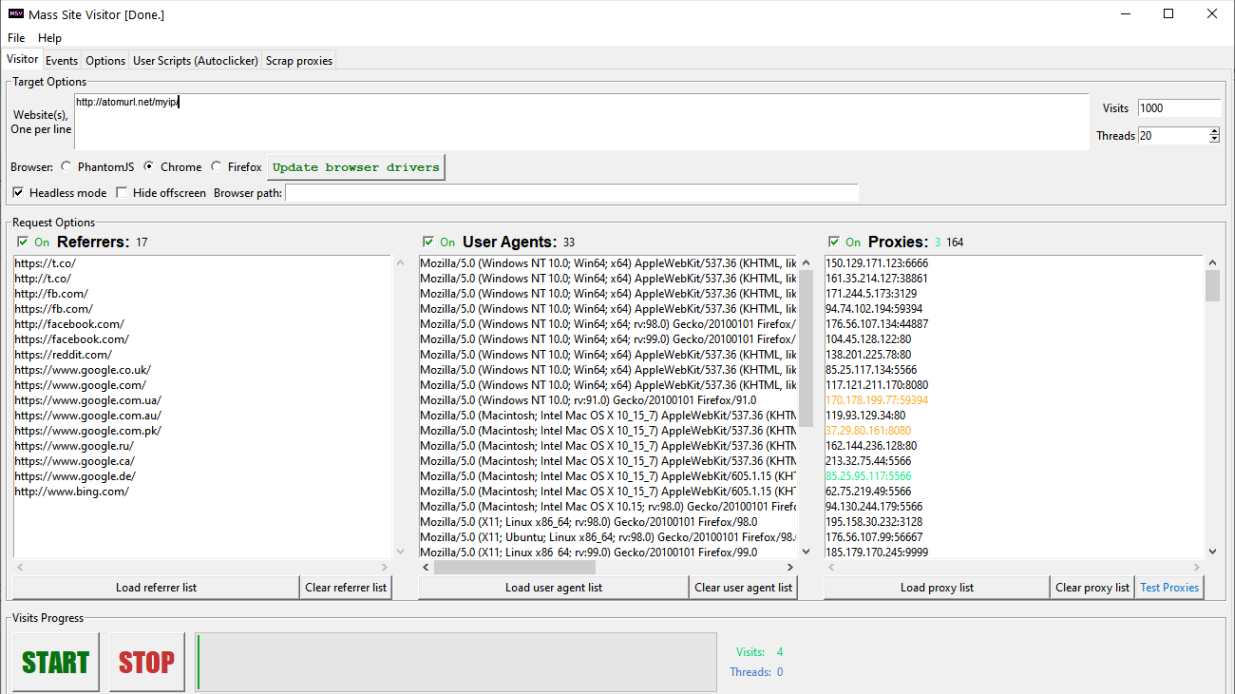
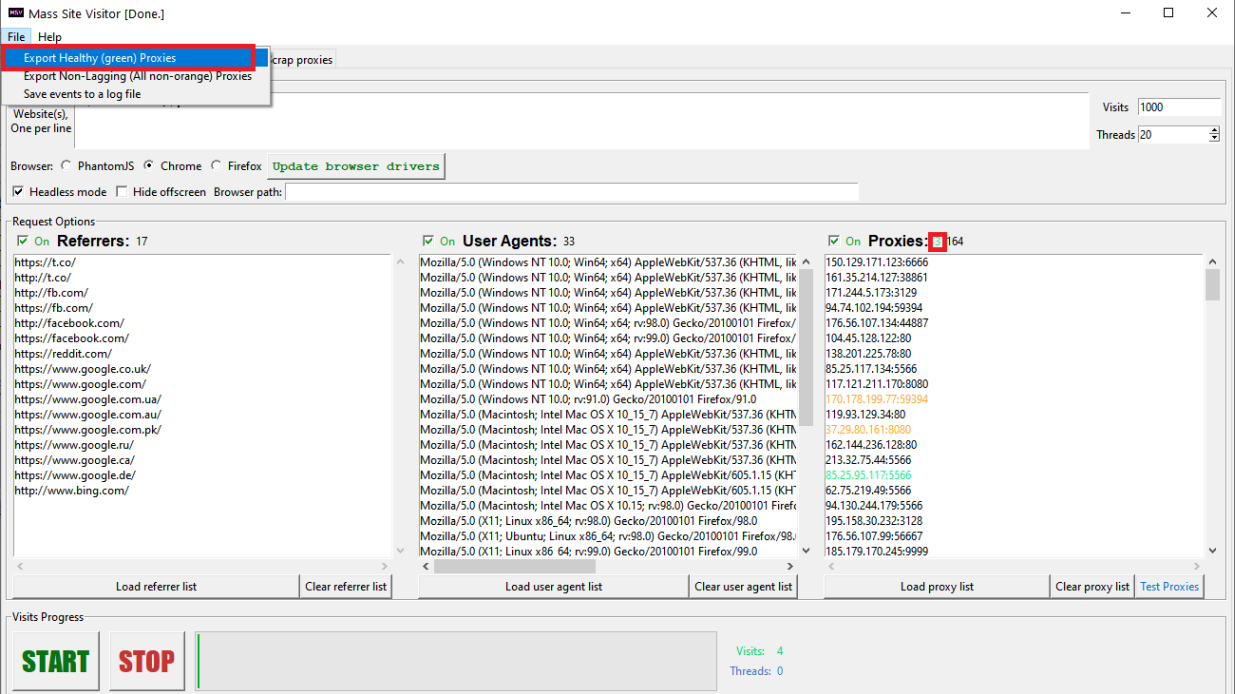
Mass Site Visitor (MSV) is designed to generate large amounts of traffic to websites of your choice through the list of proxies in a multi-threaded way using the power of your computer. It concurrently runs automated browser sessions in the background on your PC, and directs their traffic through proxies to the target website(s). MSV allows you to set visitor behavior from simple like page visiting, to automatic clicking random links and scrolling, to complex conditional clicks on any elements of your web page.
Latest and greatest video preview: auto-random scrolling and clicking: https://youtu.be/b2UgTGpEfnY
Newest and hottest video tutorial: How to mass auto click links: https://youtu.be/MwoX3euYezo
Original PoC video (visiting and affecting Google Analytics): https://www.youtube.com/watch?v=Vcx4oEvt0pI
Version 2.4.2 released (Dec 2023):
-stability improvements
Version 2.4 released (Nov 2023):
-SimilarWeb addon support for better ranking results (requires windowed chrome / firefox) - replaces Alexa bar addon, is it became obsolete-stability improvements
Version 2.3 released (Sep 2023):
-stability improvements
Version 2.2 released (Jun 2023):
-stability improvements
-cookie support (consult the pdf manual for the details for the cookies file format)
-option to disable image loading (caution: might make bot traffic more detectable)
Version 2.1 released (Apr 2023):
-Auto-Random user behavior simulation (clicking and scrolling) can work independently along with userscripts now
-fixed Windows 7 and some Windows Server versions compatibility issue
-updated all third-party dependencies to the latest version
-minor stability improvements
Version 2.0 released (Feb 2023):
-Auto-Random user behavior simulation (clicking and scrolling) - easy 1 click setup
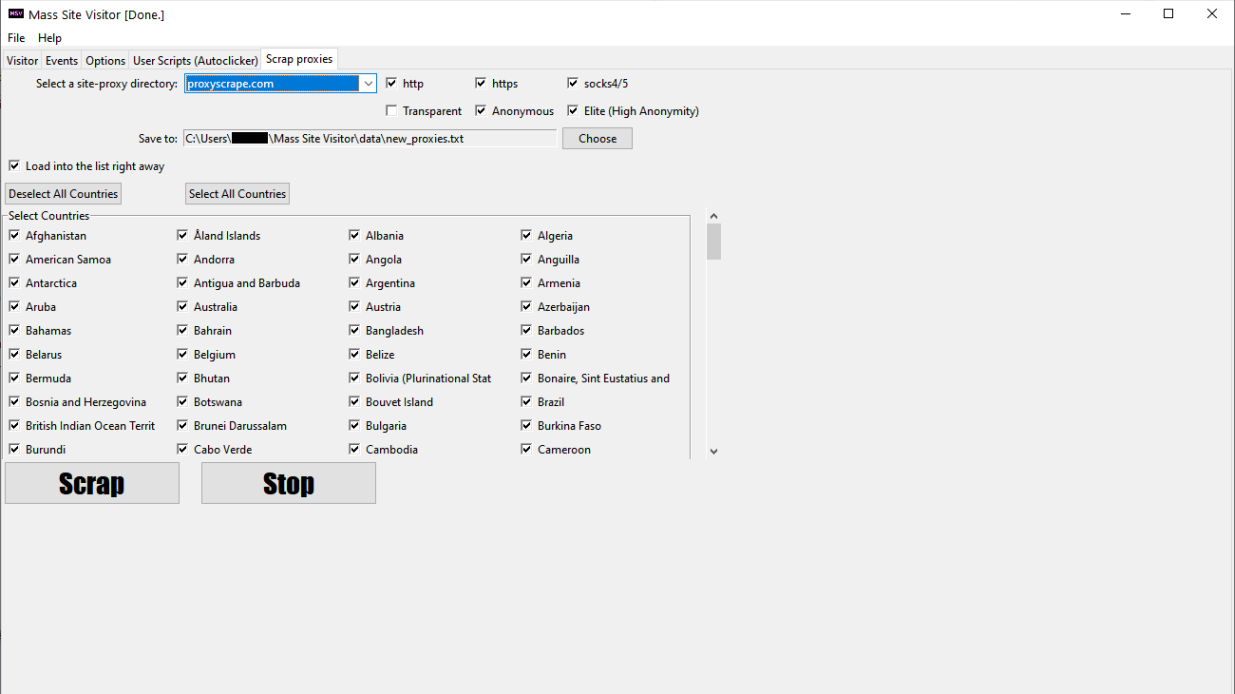
-new public proxy scraping directories to help scraping better public (free) proxies
-Improved UI for saving/discarding/resetting MSV settings
-improved performance and stability, enhanced the codebase and updated dependencies to the latest versions
Version 1.3 released (Apr 2022):
-Performance, stability improvements
-Using the latest dependencies/frameworks
Version 1.2 released (Sep 2021):
-Variety of bugfixes and improvements
Version 1.1 released (Dec 2020):
-More proxy scraping websites available
-Target specific countries by scraping proxies from these countries only
-Update all the browser drivers in one click
-Enhanced bot stealth ability - makes bot indistinguishable from regular browser by any technical means (except for behavior analysis, when too sudden changes in traffic occur, be careful and gradual, when influencing sensitive websites) (Chrome and Firefox)
Version 1.0.2 released (May 2020):
-Proxy scraping ehnancements
Version 1.0.1 released (Feb 2020):
-Proxy scraping fix for gatherproxy.com
Version 1.0 released (Nov 2019):
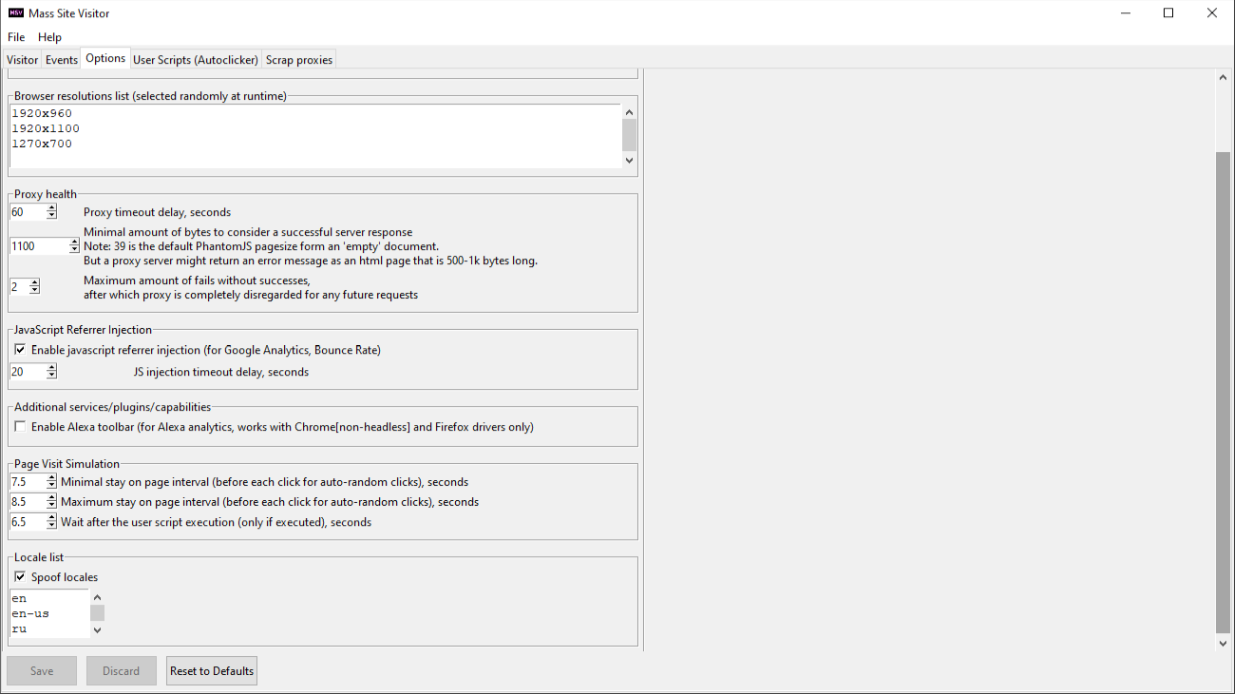
-Locale spoofing (setting browser language)
-New Selenium version used
-Latest Chrome/Firefox support
-Bugfixes, stability improvements
Version 0.7 released (Jan 2018):
-3 additional proxy scraping targets
-Bugfixes, stability improvements
Version 0.6 released (Dec 2017):
-Selenium library updated to 3.6.0 - stability improved
-Third-party dependencies added into the About window
-Open the working folder button in the Options window - for users' convenience
-Bugfixes/code refactoring/stability improvements
Latest features include:
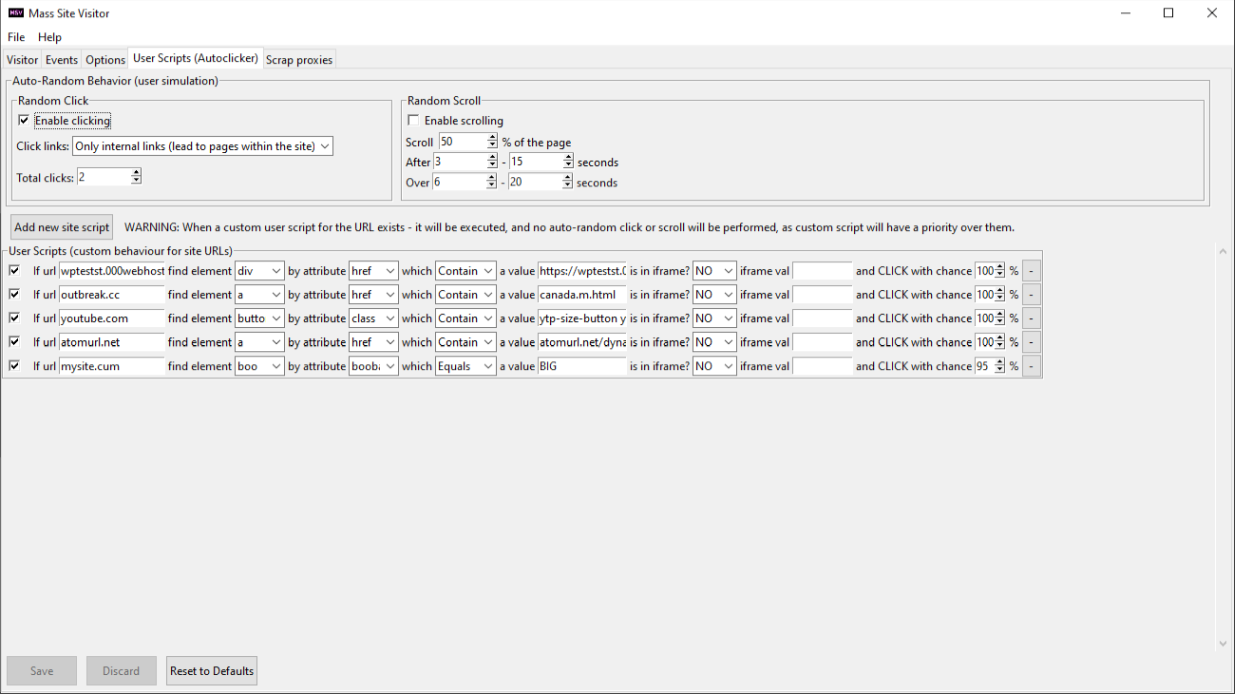
1. Auto-Random clicking and scrolling – reduce your bounce rate and simulate real user behavior on web-page with an easy setup in a couple of clicks
2. JavaScript referrer spoofing (for Google Analytics traffic sources)
3. Chromedriver (non-headless browser to influence video/audio view counts on web-sites that track the playback from visitors). Pro-tip: don’t use JS referrer spoofing with this feature, because media sharing sites don’t care much about traffic sources, that would be only useful for influencing Google Analytics.
4. Test all proxies (will use the connection timeout and number of attempts from the Options window)
5. Private proxy support, consult the manual as to how setup you proxy list to supply authentication info for a private proxy provider.
6. Editable browser dimensions. Check the Options menu, use the format, as you’ll see for the default resolutions, provided with the program.
7. Firefox geckodriver. For cases when Chrome is not enough. Nightly is a preferred version, because only it was working properly without crashes on different machines.
8. Experimental: SimilarWeb addon support for better ranking results. Warning: works stably only with chrome (windowed) / firefox.
9. Multiple web-site destinations for a session. One web-site per line in a textifield – one of those will be randomly selected each time to visit.
10. Search for the element to click within an iframe. If a link is within an embedded third-party web-page, consult the manual on how to use it. If the link isn’t in an iframe – just leave the last 2 textfields of the script as they are (one with NO, another empty)
BIG FAQ
How to use it? just unpack the archive into some folder, run the .exe file, scrap proxies, enter website url, press start, address all questions in the PDF manual, or by checking out and studying the gui – it should be pretty self-explanatoryCan i use Mass Site Visitor for youtube url? Youtube is not properly supported – i don’t guarantee any impressive results there
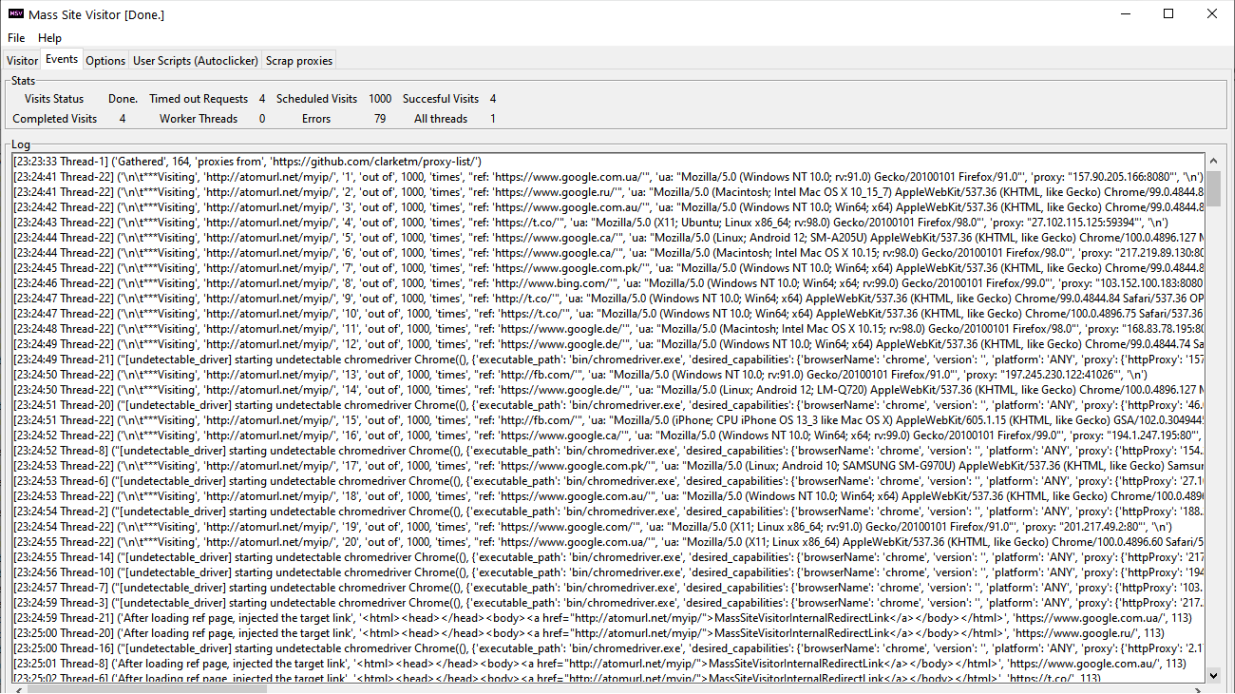
Does it take a long time to get these visitors? After running for some time – no, initially – yeah. In the beginning while the bot goes through scraped proxies, filtering out the unresponsive ones (and i have 1.5 minutes timeout because some working proxies are very busy, but they eventually work) your progress will be slow, but then the pace picks up. Additionally if you have a high stay on page interval, and stay after click on an HTML element(if set) your throughput will decrease. That is unnecessary, you can reduce those, but in some case can be used to ensure that user behavior is more genuine and page loads fully (some lagging async loads can take time to complete)
Can that bot handle low cpu usage?How many threads can a PC handle? CPU usage will increase with thread amount, and so will ram. i5 Maxwell + 8 GB ram handles 50 phantomjs threads comfortably, I can use browser at the time while running Mass Site Visitor. Generally, however many chrome tabs your PC can handle simultaneously without freezing is an upper theoretical limit for MSV threads.
Using proxies with username and password Using PhantomJs, or non-headless (windowed) Chrome it is possible, the format is: 127.0.0.1:80 u:myveryspecialname p:MySUp3R$3CuR3pa$$W0rD
My hardware is now Rayzen r5 1600AMD rx5708gb ram How long i will need for 100k visits? maybe like a week or less
I sell physical products online and I wander if your bot could be useful to promote listings on Etsy, Amazon etc. or my own website. Do you think it can help with indexing/promotion? I am not too sure about algorithms Amazon and alike you to calculate rankings, but if traffic from non-logged in users, which don’t purchase products (I mean, that would require spending actual money on purchases) influences ranking positively – MSV will work for you.Yeah, if logged in sessions aren’t important for your use.
mixcloud.com Is there a way to send trafffic to that link and create a script to press play?if i wanted to use it to increase the number of plays on a song? Yeah, it sounds possible (with the clicker feature). Although I haven’t tested MSV on this particular site
Driver version error in the Events tab of MSV. Well the error says that you have mismatch between chrome and chrome driver, so either press the update browser drivers button on the main window, or see the about window for links to chrome driver and download the one according to your chrome version, and replace it in bin folder of msv. You should download the latest versions of those drivers from the official web-sites, check these links https://github.com/mozilla/geckodriver/releases https://sites.google.com/a/chromium.org/chromedriver/downloads
Keywords, how to influence them? Keywords are tricky, and I never fully tested it, but here are a few tips some customers used successfully:You could try setting referrers for Google keywords, you might need to use a weird link like this:https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=2ahASDwqwer_ASdasdQWEEQWEASDasdQWE&url=https%3A%2F%2Fwww.asp.net%2Fmvc&usg=ASDwqeASdwqeqdafASD_3asdASDASdasd , which is the link, that leads to your site from Google search page, if you are ranking at google.Though sometimes simpler referrers might work like https://www.google.com/?q=keyword1+keyword2. But it’s not always working.Alternatively, visit Google search page, where your site is ranking, set the bot to click on the search result, that way correct keywords will most likely register in GA.
Does your tool have the Anti-fingerprint ? to bypass bot detection ? Sessions are always distinct, so fingerprinting is not likely
How many visits can do this bot a day ? up to 20K daily with one average pc, I’d say, but it highly depends on your hardware really
How much traffic can the BOT generate? How many hits will the bot deliver in an hour? Speed depends highly on the proxies (how many of them are responsive and how much do they lag), and bottlenecked by your ram (how many browsers will you be able to run in a background simultaneously). With public proxies and 8 GB of RAM I was able to run 50 threads, and get like 400 views an hr. Though it can be much higher, if proxies are responsive and fast; or can be even worse, if no good proxies are at hand. In daily terms it will ?fluctuate from couple of 1000’s, to couple of 10000’s on average for an average desktop PC. But sky is the limit here, if you have access to a lot of fast responsive proxies and a top-tier hardware
Country-specific traffic, targeting particular countries You can scrap proxies from any country of your choice from several free proxy websites using MSV, which will make the generated traffic country-specific. You can also load your own list of any proxies from any countries. Locales are available also, you can set browser language, works best for chrome or Firefox
Can MSV do more than one website at a time ? you can enter several websites simultaneously
Where can I get a paid quality proxy list?
Here’s a good one
An this one is nice as well
I want to use your software to click my competitor ads on amazon website by searching the product on the website and click the ads. Is it possible? If their products are available on the search page, then it should be doable by:1 targeting in msv url amazon.com/some-kind-of-search-url2 using instructions in the PDF manual, setting the bot to click on ad on the search page, it will work if your competitor’s ads have like a unique id, or text or something in the HTML code of the page. You can check that out using browser inspection.
Does this increase your google rankings etc, is it based on keywords? yeah, you can influence GA, and other js-based analytics engines, as shown in demo video, as for keywords there’s a hack, which can work, but not completely reliable
Can you explain how it works? bot works by running automated browser sessions in the background, on your pc, using proxies
Reducing the bounce rate ? You could reduce it drastically by using MSV clicker feature basically, use the clicker feature to have the bot visits click on a link to some other page of your web site Use clicker feature – set the bot to click on some internal link on your website. If you want visits to have smaller bounce rate, you’d have to use the clicker feature (which is described in the pdf manual), set the bot to click a few links with different probabilities, that would count as 2 pageviews per visitor, an reduce the bounce rate.
Is it safe for AdSense websites? yes, it doesn’t click on ads by default
Does your bot clicks on Google Ads? you can set the bot to click on as links and banners, etc. But it could get you banned. Your clicks to ads essentially never convert – obviously fake bot click cannot make a real purchase with real money, the ad provider might see at a very suspicious trend.
Can i use MSV for bitly short links? Kind of yeah, clicker feature will be helpful for you, but the risk to get banned is pretty significant But it’s risky, and you have to start small, and there will always be a chance to get banned. Clicker feature of msv lets you press those skip ad/continue links like a real user would
Google ad clicking If you are thinking about clicking ads on your sites with bot traffic I would like to at least discourage you from doing so from public proxies. Any PPA network is a bit too smart for such obvious tricks, and the amount of money gained from using bot clicks will not out-weight the significant chance of being banned and never seeing your $10, which the bot traffic created you over a couple of days I guess if you have some private proxies (but those cost money, and you have to seek out providers with ‘unsullied’ IPs, which nobody else used for some kind of spam or whatever) that might yield some modest results.
Can i increase my Alexa rank using this bot traffic? yeah, using Alexa addon option Firefox + Js injection + Alexa add-on used to be the go-to combo for Alexa, now non-headless chrome might be better
Any Google Analytics-specific settings for MSV? Any browser + JS injection is perfect for GA
Please tell me whether your bot will be launched in windows 32 bit? MSV is a 64 bit only software
The software doesn’t work. Share details of your experience, logs, screenshots, if you expect any help
Will it increase website rank in google or alex rank? Google ranking is more complex than that, backlinks are a factor, and for long term high ranking you need quality content on your site and returning users. BUT traffic bots and tweaking your GA stats sure will have a boost for your ranking. Alexa rank can be influenced with Alexabar add-on, and non-headless chrome, or Firefox
From your experience, what are the best selections (in options panel) in order to get more pageviews in GA ? I’d say if traffic sources matter to you – have JS injection option enabled, it’ll slow down page loading, but referrers will get registered in GA. Have proxy timeout to somewhat above a minute if you’re using public proxies – a lot of the lag, but tend to respond after waiting for a while.For bounce rate – set the bot to click on some link, which leads to a different page on the target website, therefore making it look like the visitor didn’t just bounce (entered some page and left without checking the rest of the website). Have page stay intervals for like 5-15 secs or something like that, it will be slightly slower, but if you have some extra javascript on the page – the delay might help to load page more fully before leaving/doing a click. Unless Alexa rank and/or video/audio playback matters – just use headless Chrome. If you don’t have any problems – just disable page snapshot saving – they are only useful for diagnosing how the target page was loading (especially yin the headless browser)
What are the Threads? Threads are just what they are – threads. In the context of MSV they basically mean how many browser sessions will be running in parallel on your computer.
I try to use a long url referral but it’s not working The standard referrer list, provided with MSV contains http://t.co as referrer, if you are only interested in twitter as referrer, use the list that contains just that link, because as far as i know, twitter processes all it’s external links through t.co domain, an all twitter referrers pretty much look like that. Don’t forget to enable the JS referrer injection option, like it is shown at the beginning of the demo 3 video, it’s needed for different JS-based analytics (like GA). Also, some public proxies like to strip the referrer, so some of your traffic will end up being direct no matter what (but the percentage will be at most 20%, like in the demo videos).
(‘Error launching a’, ‘Chrome’, ‘browser.’, WebDriverException(‘unknown error: failed to wait for extension background page to load: chrome-extension://cknebhggccemgcnbidipinkifmmegdel/html/background.html\n from unknown error: page could not be found: chrome-extension://cknebhggccemgcnbidipinkifmmegdel/html/background.html’, None, None)) Try disabling the Alexa addon, or disabling headless mode for Chrome (if you need to have the Alexa addon enabled)
I want to click on google ads ads. Do you have a chance to give me more detailed information about choosing ads in the “user script” tab? You know ads, classes are constantly changing, which variable should I base on? Depends on the ad provider used, really. You can also use “Contains” selector (instead of “Equals”) with MSV for the value of attribute, if for instance “class” attribute always has a different value, but some part of it is always present. You can also use any other attribute, not necessarily “class”. Also, if you are placing your ads into a “div” container, you can give it and “id” and try setting a click on that “div” by its “id”. Just make sure that the div isn’t larger than the ad, and doesn’t contain anything besides the ad. Usage of other container tags, other than “div” is also possible.
Influencing Pinterest ranking From my customer’s success stories: If you make the referral actual Pinterest pin links from your site, Pinterest ranking will go up too- since the bot visits Pinterest first. It doesn’t even have to be the correct pin for the webpage – load images, non headless.
Other common issues when running MSV
1. The program itself communicates with the headless browser through the socket interface, so to allow inter-process communication you will most likely have to allow Windows Firewall to give both PhantomJS (chromedriver, geckodriver) and MSV the green light (usually, firewall will straight up ask if you want to allow the program to communicate through network)
2. Don’t forget to reduce thread count if you are using low-end machine. Having several dozens of threads running browser sessions that are being created/destroyed constantly, and are trying to load some web-page is a performance-heavy task.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}