

Data Scraper for websites
Data Excavator – powerful C# server for crawling, scraping and saving any data from websites. With the data excavator, you simply can scrape any data from any website and export it into XLSX / CSV / MySQL / JSON. It’s a really simple and fast solution with minimal entry point for everyone who want to mine data and don’t want to read many of tutorials.Scraping process working based on .css and x-path selectors. Application includes crawling server, grabbing server (scraping server) and IO server. Each server written in pure multi-threaded model. Do you have 8-cores processor? Good. May be, 12-cores? Very good! The data excavator is directly depended from your PC quality – he can works at powerful servers. In general, with a good hardware, you can boost the data excavator to scraping websites in “monster-mode”, and make 100, 500, 1000 scraping requests per second. Do you really want to making professional data mining? Ok, then just use the Data excavator and forget about other ways to mine data. Our solution is the really fast native server, written with pure quality and with the best specific algoritms.
Most of existing data scraping solutions from competitors works pretty linear – you must do every scraping step yourself with browser plugin. Alternatively you must to use page-to-page switching with pressing “Scrape data” magic button. Of course, there is a lot of professional data-mining solutions with high price and original quality. But there is not so many good solutions with good price and performance.
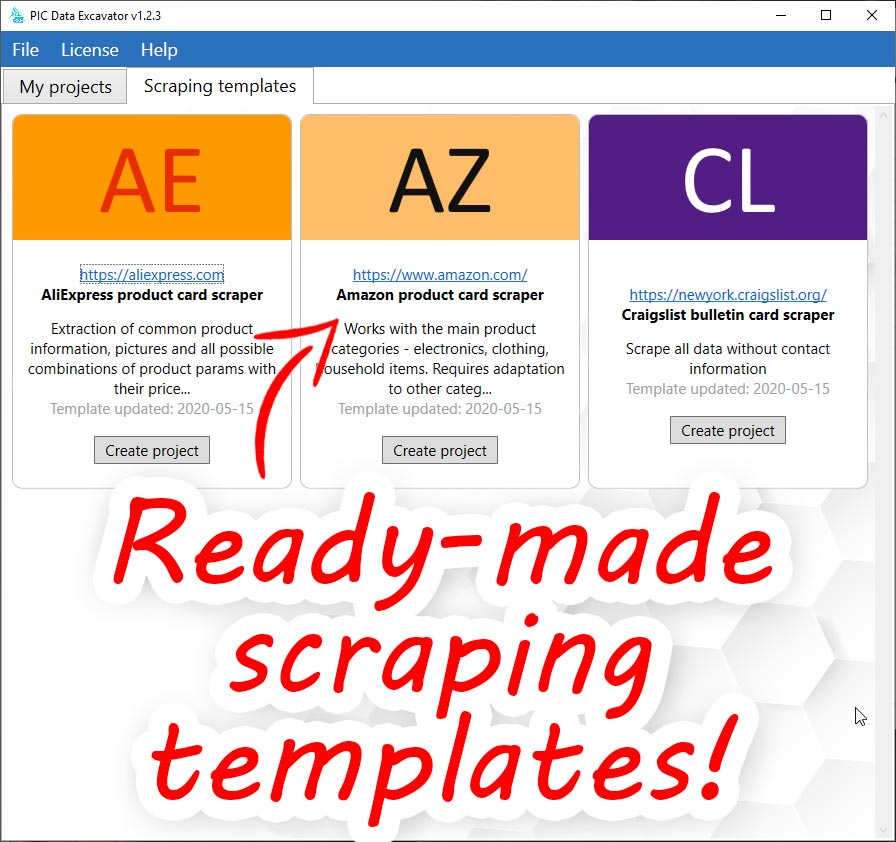
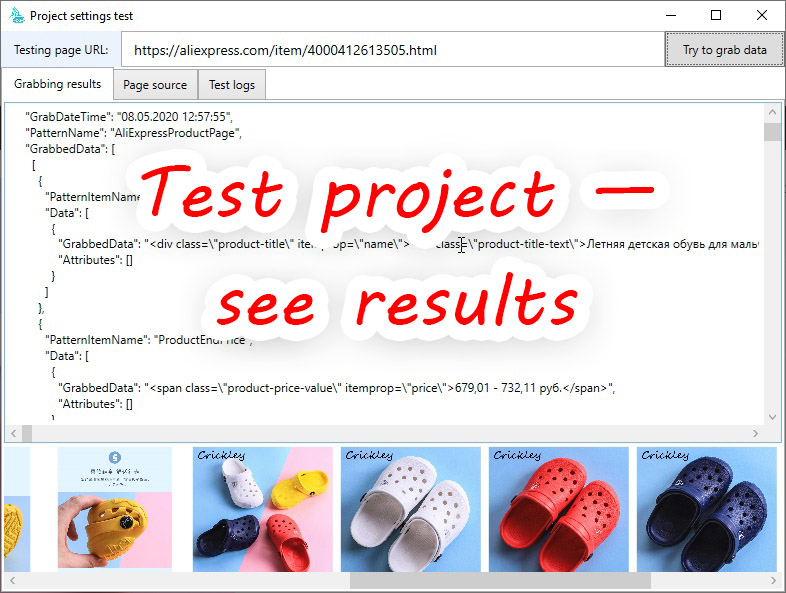
The Data Excavator can be used in most of situations when you need to extract any-typed data from any website. May be, you want to create a e-commerce project and you search for a goods data source? May be you want to build a service for prices comparing? May be you are a big data specialist and must prepare some data set for analysing? Any task in data scraping that you can imagine you can solve with the Data Excavator application. For example, take a look at how well our program manages to extract data from the Aliexpress website. We simply take any page and sequentially extract all data from it. You don’t need any settings – we have a ready-made configuration.
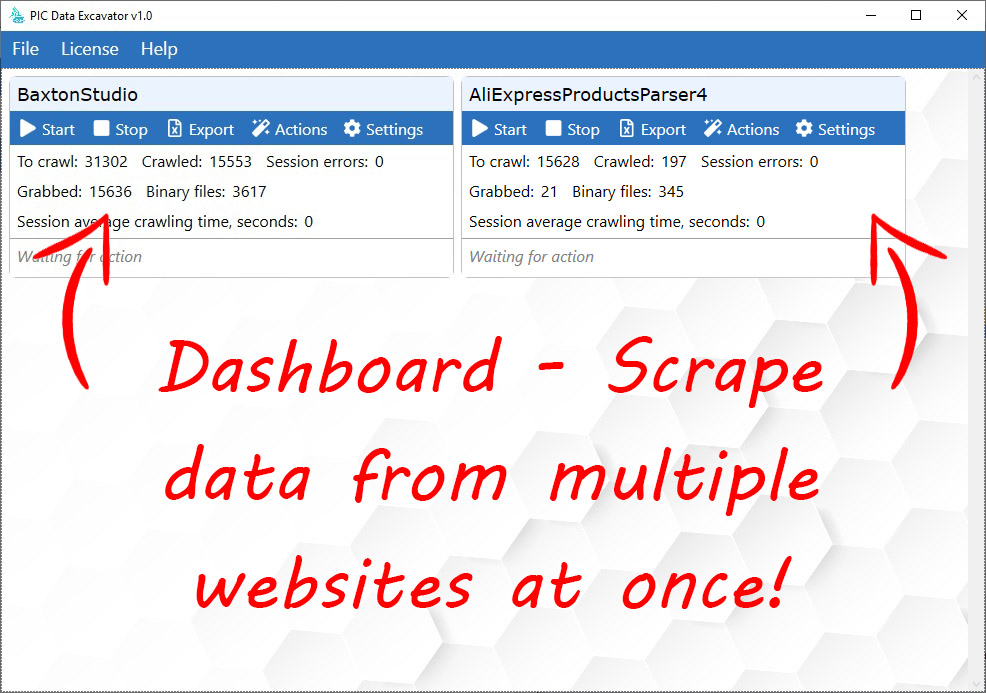
What are the key differences between our application and others? We offer a complete scraping server. It literally does everything you need to extract data, from multiple settings and automatic .css selectors, to exporting data on the fly. Based on our application, you can create large systems for automatic data scraping and analysis. Our application includes many comments on the source codes. You won’t have any trouble understanding the interface structure and calls to system libraries. Our main pride is multithreaded scraping. We have made the application parallel in everything that was possible. You can create multiple projects and extract data from multiple sites simultaneously. Each project has its own thread pool (oh yes!) which can be increased or decreased. Each project has a separate thread pool for scanning pages, and a separate thread pool for parsing downloaded pages.
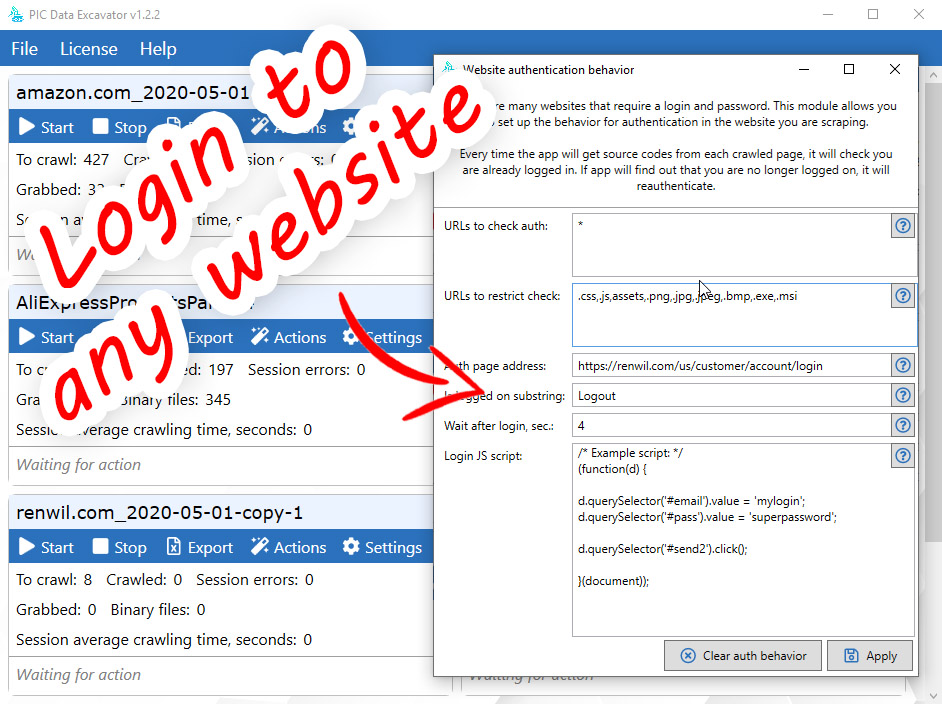
Our application is based on the Chromium Embedded Framework (CEF) – that is, it has a full-fledged Chromium browser built into it. This allows you to extract data from any site, even those where content is not immediately downloaded or requires a login. This fundamentally distinguishes us from our competitors – our application is suitable for scraping almost any site.
How it works
Our application is written in C#. Yes, it’s a full C# (.NET) scraping server. We used a multi-threaded model in order to extract data from any site as fast as possible. Our application supports authorization and interaction with sites via JS. We try to make the interface simple, under which there is a fairly powerful engine.What tasks you can solve?
- Scrape any data from any e-commerce websites, like: amazon, ebay, aliexpress, walmart and many others.
- Scrape any data from any social network: facebook, twitter, instagram, linked in and others.
- Scrape any data from any cryptocurrency exchange website.
- Scrape any data from any supplier website.
- Export of scraped data: .xlsx / .xls / .json /.csv and others.
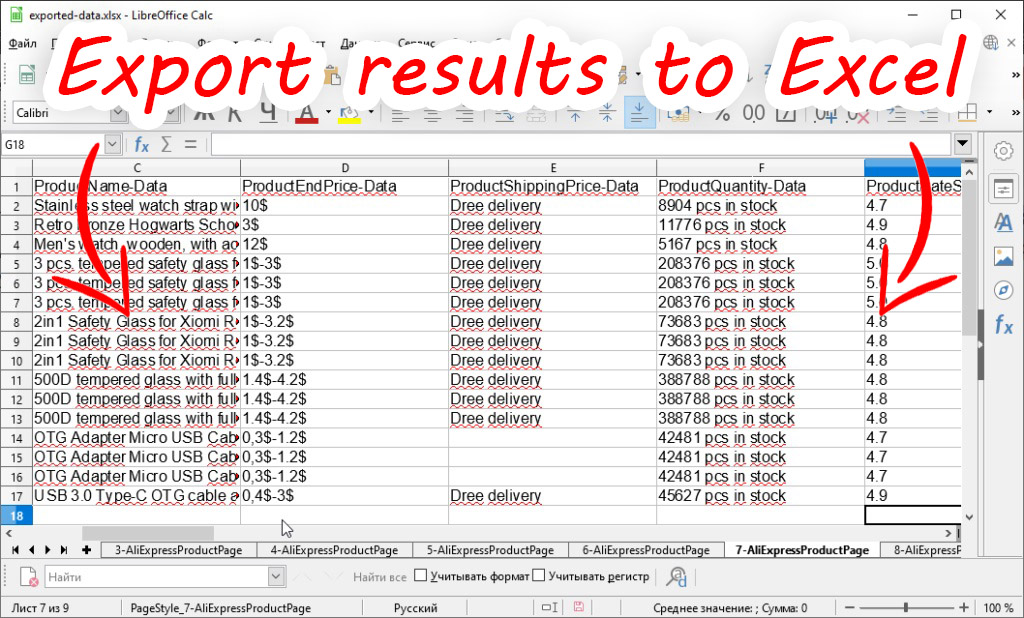
Export of results
Once you have collected data from some site, you can export it. We support export in xlsx, csv, json, mysql formats. We write text data into a file and place images from the site in a folder next to the file. These images are linked to the data via the “images” column in the table, or via the corresponding parameter in the JSON object (depending on the export format you choose).Special: working with pictures and BLOB data
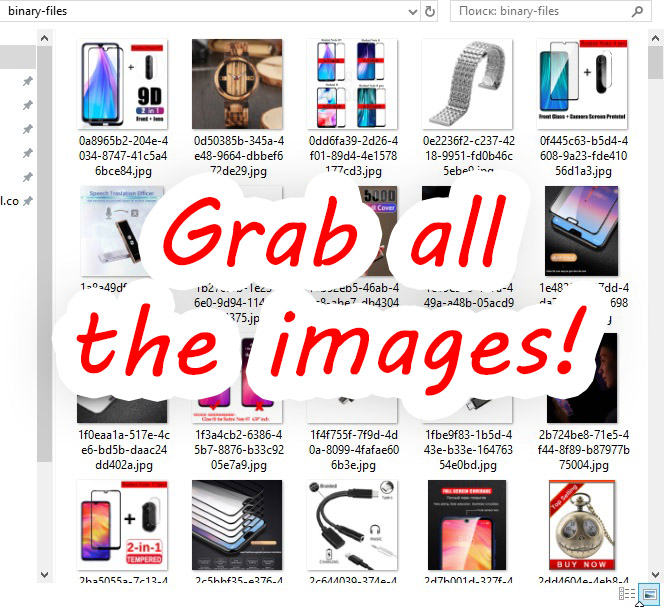
Our system is able to work with images and other binary files. You can extract literally any information from the target page – images, media files, binary data and so on. Even if the image is packaged in the data:[blob] format, the system will correctly process it. All images are stored in files on your hard drive. When exporting, we collect the archive, which contains the exported data, as well as a set of images.App modules and libraries
Our scraper is written in C#, platform .NET Framework. It includes the following modules and libraries:- CEF (Chromium Embedded Framework)>
- CEFSharp – connector between C# and CEF
- EPPlus – working with Excel
- RestSharp – working with remote calls ($_GET / $_POST)
- ExcavatorSharp – library for parallel crawling and scraping
- HtmlAgilityPack – parsing data from DOM
- Newtonsoft.JSON – packing data into JSON format
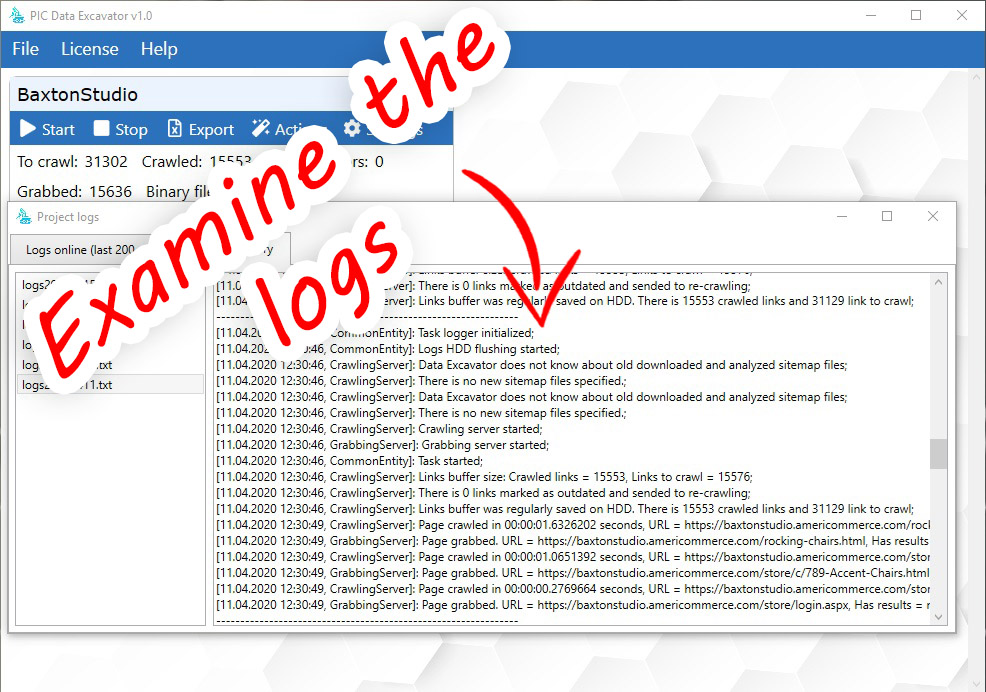
- log4net – data logging
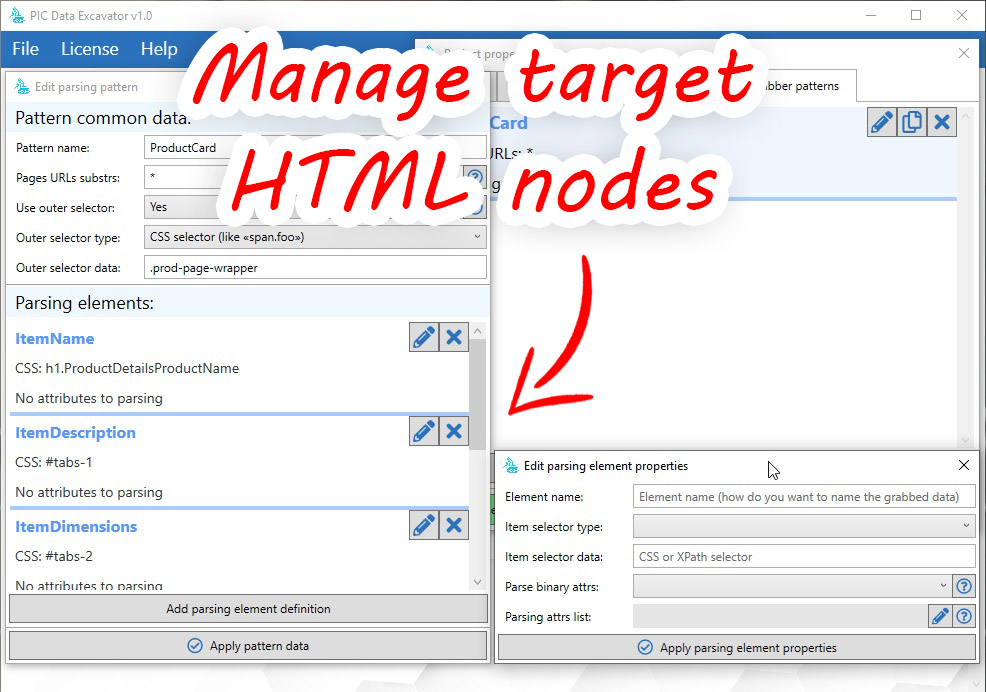
As a minimum of knowledge you should understand how .css-selectors or xpath work. You should also be familiar with general web data extraction skills such as proxying, $_GET and $_POST queries, page scanning management through templates and regular expressions.
Also, if you want to extract data to fill your site, you must understand that the system scans the data and then exports it to some format, or sends it via some http(s) link. The system does not know how to automatically insert data into your site.
Additional options:
Fully free support! We are literally just entering the market and recruiting an audience for our solution. We went crazy and laid out the source codes for our application. If you want to build a solution for data scraping based on our experience, we will be glad to advise you!Features:
- Pure multi-threadeded scraping (you can scrape many different websites in parallel)
- Multithreaded crawling – get data from website in parallel mode
- Browser-engine crawling – parse data from downloaded pages in parallel mode
- Support for multiple proxy servers
- $_GET and $_POST user args – download pages with set of args
- Dynamic content crawling – get content created with JS, ActiveX and other. Wait for AJAX calls
- Interaction of user JS-code with pages of the site
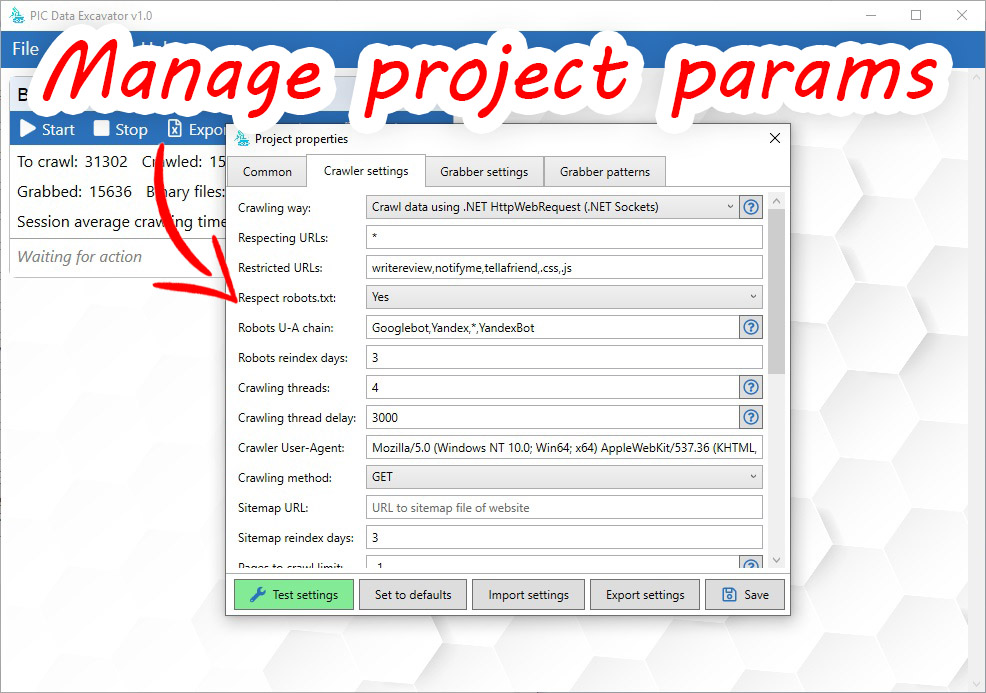
- Robots.txt ans Sitemaps support
- Pages reindexing support
- User-defined crawling behaviors
- Respect or disrespect for selected links
- Analysis of robots.txt under the selected user agent
- Multi-dimensional data extracting
- Multithreaded data extraction
- Exporting data: .xls, .xlsx, .csv, .sql, .json
- Exporting data online via HTTP url
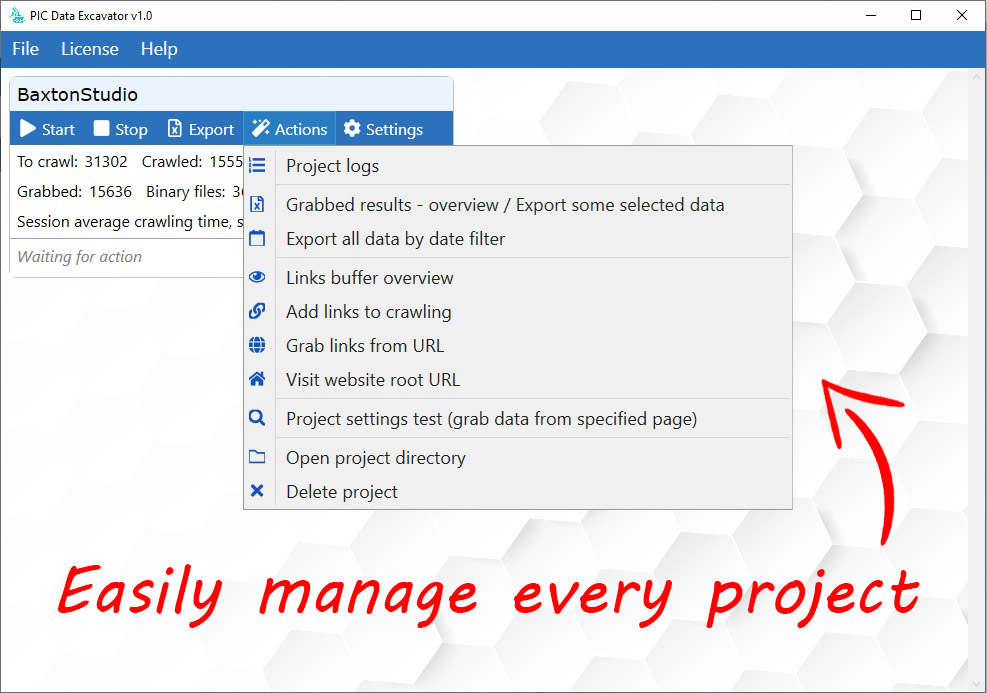
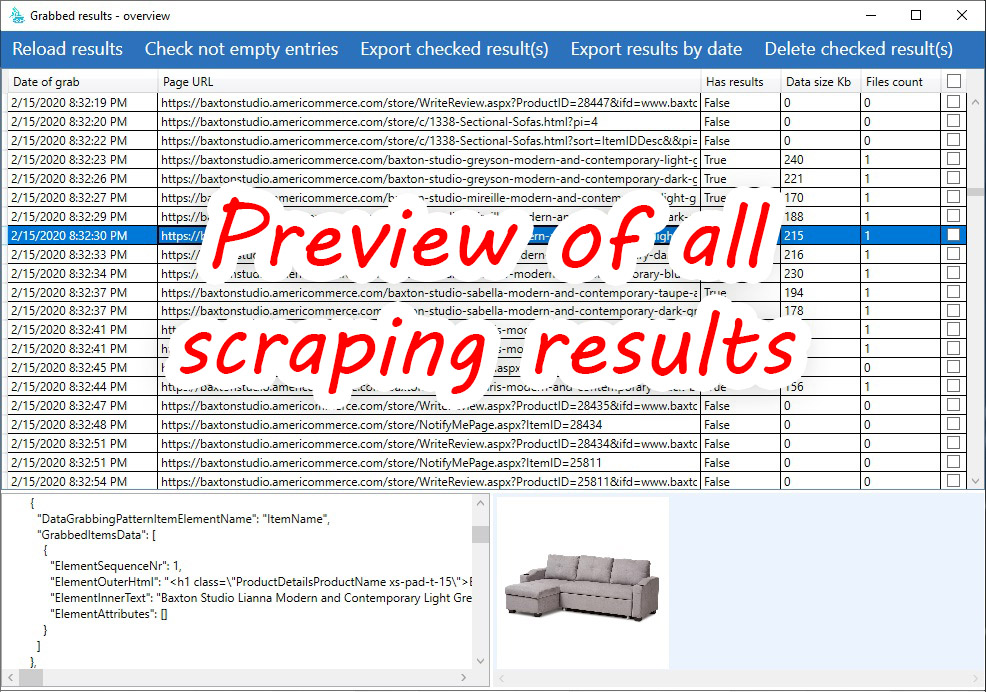
- Overview grabbed data into UI
- Import&Export projects settings
- Project settings testing on specified page
- Grab only links from specified page (if you want)
- Project performance metrics board
- Forcing specified links reindexing
- Grabbing website links administration panel
- Projects interactive dashboard
- Supports attributes downloading – blobs, images
Starter guide:
You can use our application both for simple data scraping and for creating your own applications. If you want to simply extract data from a certain site – use Setup and install the already assembled version. If you want to develop – use the Visual Studio project.How it works for end-user:
- Create new project and complete project settings (or use default settings set)
- Specify a set of links to scraping
- Start project
- Wait while application will scrape specified links
- Export data to preffered format, like a .xls / .xlsx /.csv / .json
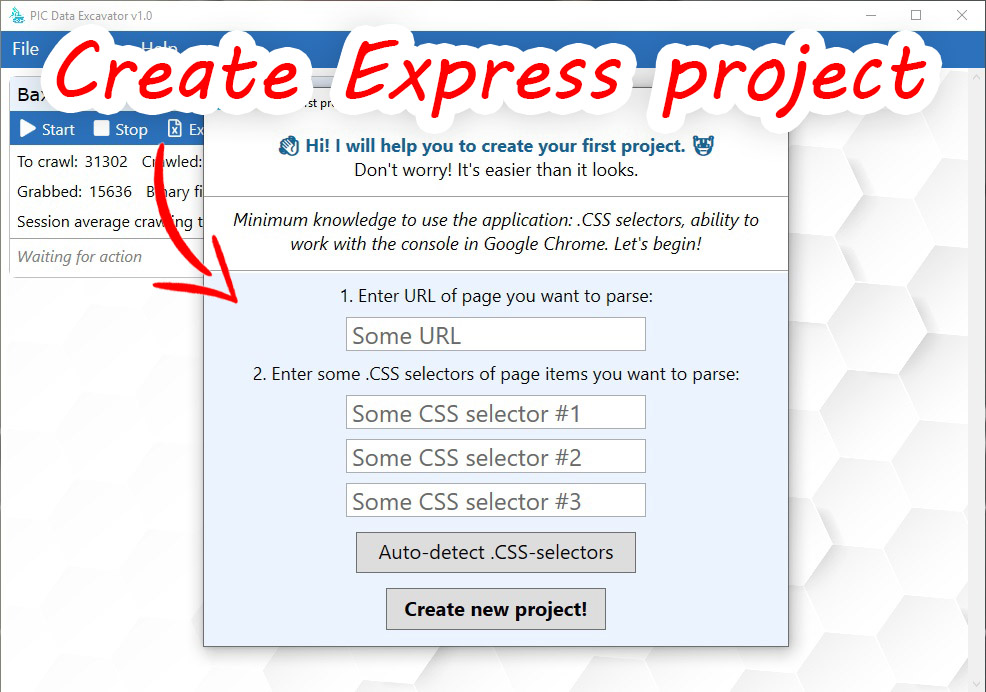
How to create new project (less then 3 minutes):
- Click on “New project (express)”
- Complete target website address
- Click on “Auto detect .CSS-selectors”
- Click on “Create new project”
What scraping tasks can I solve with the application?
With our C# scraper you can extract data from most well-known sites. Basically, it doesn’t matter what the site looks like or how it displays the data. Even if a site requires a login and password, or displays dynamic content with a delay – we can still extract data from its pages. You can scrape data, for example, from the following websites:- Amazon.com
- Walmart.com
- Aliexpress.com
- Ebay.com
- Google.com
- Craigslist.org
- Sears.com
- Kroger.com
- Costco.com
- Google.com
- Bing.com
- Wikipedia.org
- Nytimes.com
- Nypost.com
- Washingtonpost.com
- Wsj.com
- Hr.com
- Iherb.com
- And much more!
Requirements for data scraper usage:
- VC++ 2019 Redistributable
- .NET Framework 4.7.2
- X64 processor (because most of scraping tasks uses 1Gb of RAM as minimum)
- Free space on HDD (1Gb+)
- Windows 7, Windows 8, Windows 10
- IDE: VIsual Studio 2019 / Developers only
Success story
Click on image to read more, or follow direct link.Links and docs:
Website URL: https://data-excavator.comCommon questions and UI: https://data-excavator.com/faq/
Core library information: https://data-excavator.com/excavatorsharp-web-scraping/
Core library docs: https://data-excavator.com/excavatorsharp-docs/
Contact us: https://data-excavator.com/contact/
If you are an developer, see readme file after purchasing.
Extra services in data scraping and lead generagion:
Here are links to useful services for data scraping and lead generation. We use them ourselves and can recommend them to our clients.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}