

What Can You Do With This Plugin?
Crawlomatic Multisite Scraper Post Generator Plugin for WordPress is a breaking edge website crawling and scraping, post generator autoblogging plugin that uses website crawling and scraping to turn your website into a autoblogging or even a money making machine!Get content from almost any webpage! You no longer need API’s which requires registration and provides limited access, also you can retrieve data from non API providing websites. Schedule it for once and let it autopilot your posts 7/24 for you like a master!
How does it work?
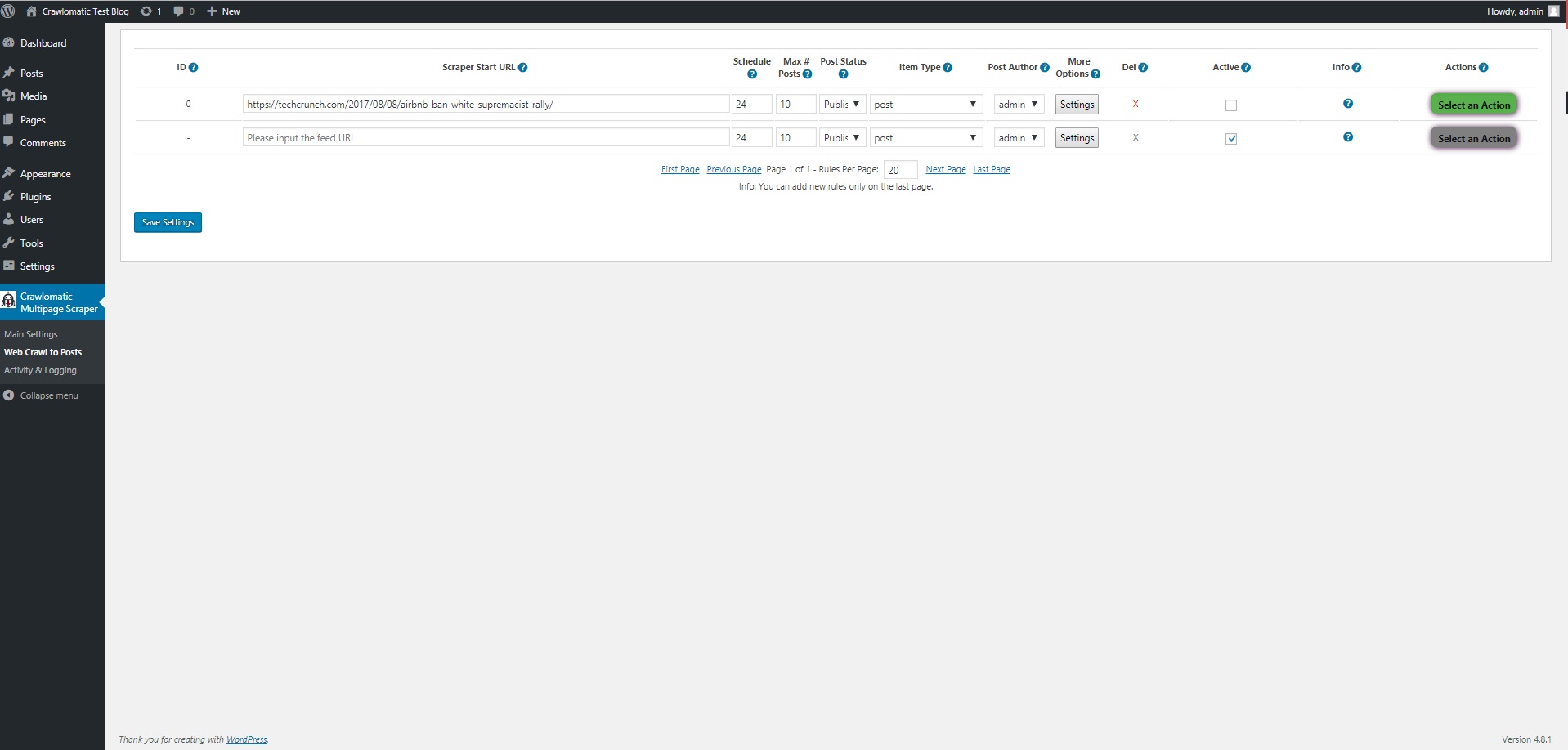
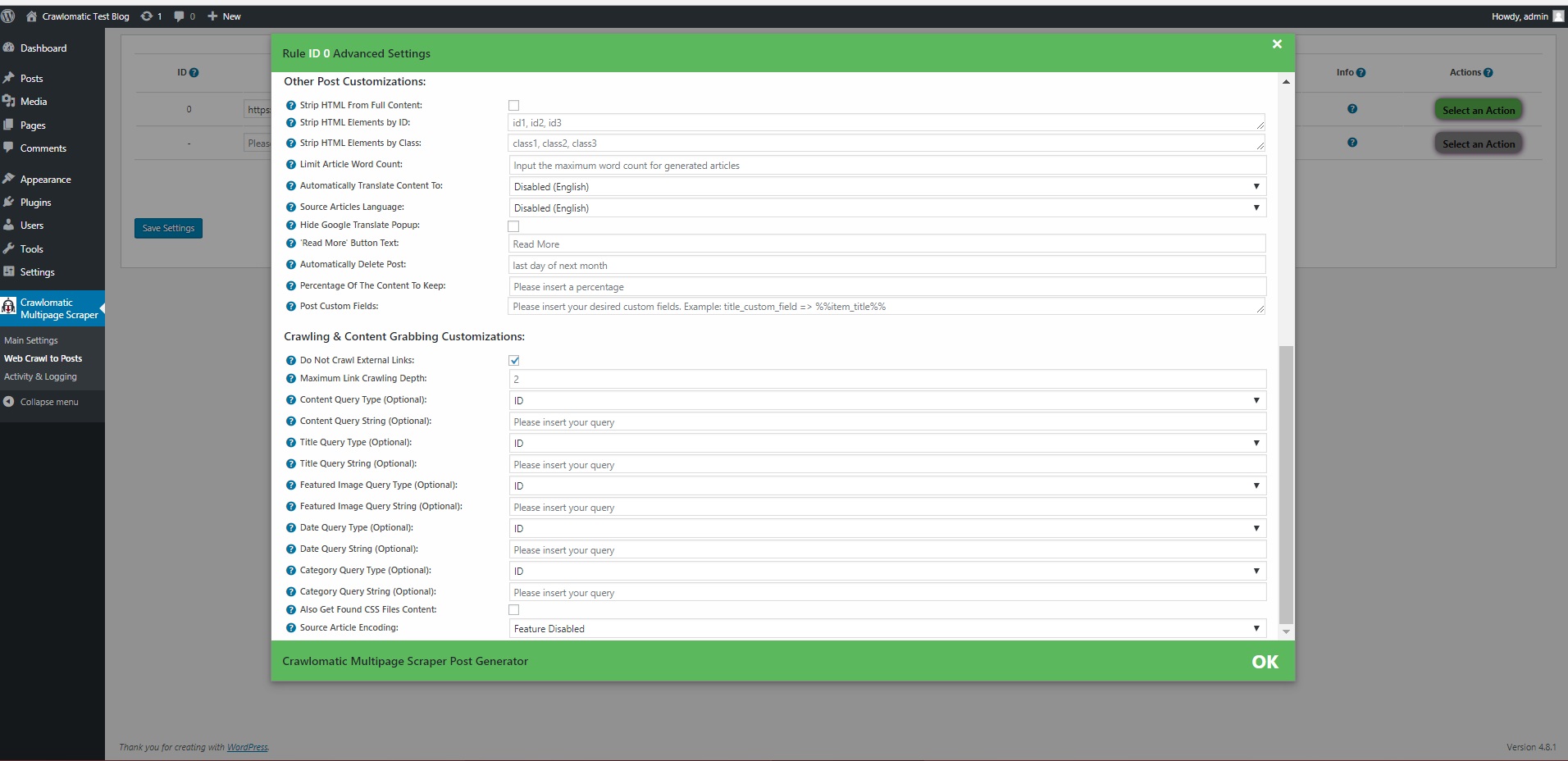
This plugin will crawl the seed URL you give it (crawling means that it will search all links that the webpage contains) and will visit and extract content from each crawled URL. The crawling process is customizable: you can set the crawling depth, crawling rate, maximum crawled article count, crawl only links with specific class or ID and many more customizations.
If you want to understand how the new live scraper shortcode works in real-world scenarios, including selector types, caching behavior, character encoding handling, and advanced parsing callbacks, the complete usage guide is available in the official documentation: Crawlomatic Multisite Scraper documentation. It explains exactly how to configure scrapers safely and efficiently, even for complex or JavaScript-heavy websites.Beyond the live scraper, Crawlomatic can be used to build full-scale autoblogging systems based on crawling and scraping rules. From defining start URLs and crawl depth to extracting titles, images, categories, and full article content, every step is documented with practical examples here: advanced Crawlomatic rule configuration guide.
If you plan to fine-tune performance, avoid duplicates, control crawl delays, or apply advanced content filtering and rewriting, the documentation also covers all available settings in detail, including regex usage, XPath queries, automatic translation, and post update logic. You can review the full reference at any time here: Crawlomatic plugin settings and shortcode reference.
Whether you’re using Crawlomatic as a lightweight live data scraper or as a powerful content automation engine, the documentation is designed to give you full control while keeping setup fast and predictable.
Crawlomatic v2.0 update
In the v2.0 update, a new live scraper shortcode was added to the plugin: [crawlomatic-scraper]. This new feature makes this plugin an easy to implement web data extractor for WordPress. As a result, it can be used to display real-time data from any websites directly into your posts, pages or sidebar. It also temporarily caches the scraped content, so your website will not over use on resources. You can use this plugin to include real-time stock quotes, cricket or soccer scores or any other generic content from public domains!New features included in this update:
- Scraped output can be displayed through custom template tag, shortcode in page, post and sidebar (through a text widget).
- Configurable caching of scraped data. Cache timeout can be defined in minutes for every scraped data.
- Configurable Useragent for your scraper can be set for every scrape.
- Configurable default settings like enabling, useragent, timeout, caching, error handling.
- Multiple ways to query content – CSS Selector, XPath or Regex, Auto Detection.
- A wide range of arguments for parsing content.
- Option to pass post arguments to a URL to be scraped.
- Dynamic conversion of scraped content to specified character encoding to scrape data from a site using different charset.
- Create scraped pages on the fly using dynamic generation of URLs to scrape or post arguments based on your page’s get or post arguments.
- Callback function for advanced parsing of scraped data.
Check the official documentation of the v2 update, browse through examples and check FAQ for crafting a perfectly optimized web scraper.
More about the plugin
You can scrape content from almost every web site that you open in your browser. If the content is loaded using JavaScript, the plugin can be combined with PhantomJS to scrape also JavaScript generated content.Also, you can automatically generate unlimited number of custom website crawling and scraping.
Other plugin features:
- v2.5.5 update: Automatically update scraped posts/pages/products if the source site changes + unpublish (set as draft) the post/page/product if the scraped URL is no longer available on the source site (optional features, can be enabled/disabled)
- v2.5.1 update: Scrape WooCommerce product variants from other WooCommerce/Shopify stores
- v2.5.0 update: Scrape search engine results for your custom keyword searches, from Google or from Bing. Check the tutorial video of this new feature.
- v2.4.1 update: Scrape product image galleries for WooCommerce products (for non-product post types, post attachments will be created from the scraped images)
- v2.3.5 update: Execute your own JavaScript code on the scraped HTML and scrape the results – this feature is available only when headless browsers are used for scraping (Puppeteer/Tor/PhantomJS) or HeadlessBrowserAPI
- v2.2.1 update: Crawl RSS feeds for links and scrape articles listed in them
- v2.2.0 update: Use HeadlessBrowserAPI to scrape JavaScript Generated HTML Content from any website on the internet without the need to install anything (besides this plugin) on your server – tutorial video
- v2.1.0 update: Scrape .onion websites from the Dark Web using the Tor Browser and Puppeteer! – tutorial video
- v2.0.0 update: Live Scraper shortcode added for even more crawling control and scraping power: [crawlomatic-scraper]
- v1.7.1 update: Sitemap crawling supported – video tutorial
- v1.6.5 update: Visual content selector support added – video tutorial
- v1.6.0 update: Added the ability to make screenshots of crawled pages and use them in generated post’s content – video tutorial
- v1.4.8 update: Added JavaScript execution support for crawled pages – requires PhantomJS installed on server – How to install PhantomJs? – video tutorial
- v1.4.4 update: Added the ability to set multiple proxies for crawling pages. The plugin will select one at random at each page access
- v1.4.0 update: Added the ability to paginate crawling (crawling for articles will continue on the next page of the seed page).
- v1.4.0 update: Added the ability to import product prices for crawled products (WooCommerce compatible) + dropshipping price automatic modification – video tutorial
- v1.4.0 update: Added the ability to increase imported product price by a fixed number or to multiply it with a predefined number (great value for dropshipping!)
- v1.2.8 update: Added paginated post importing support (into a single crawled post) Check: VIDEO.
- v1.2.4 update: Added the ability to set proxies for crawling pages
- v1.2.3 update: Added an option to crawl the page from Google cache when direct crawling fails (blocked)
- Google Translate support – select the language in which you want to post your articles
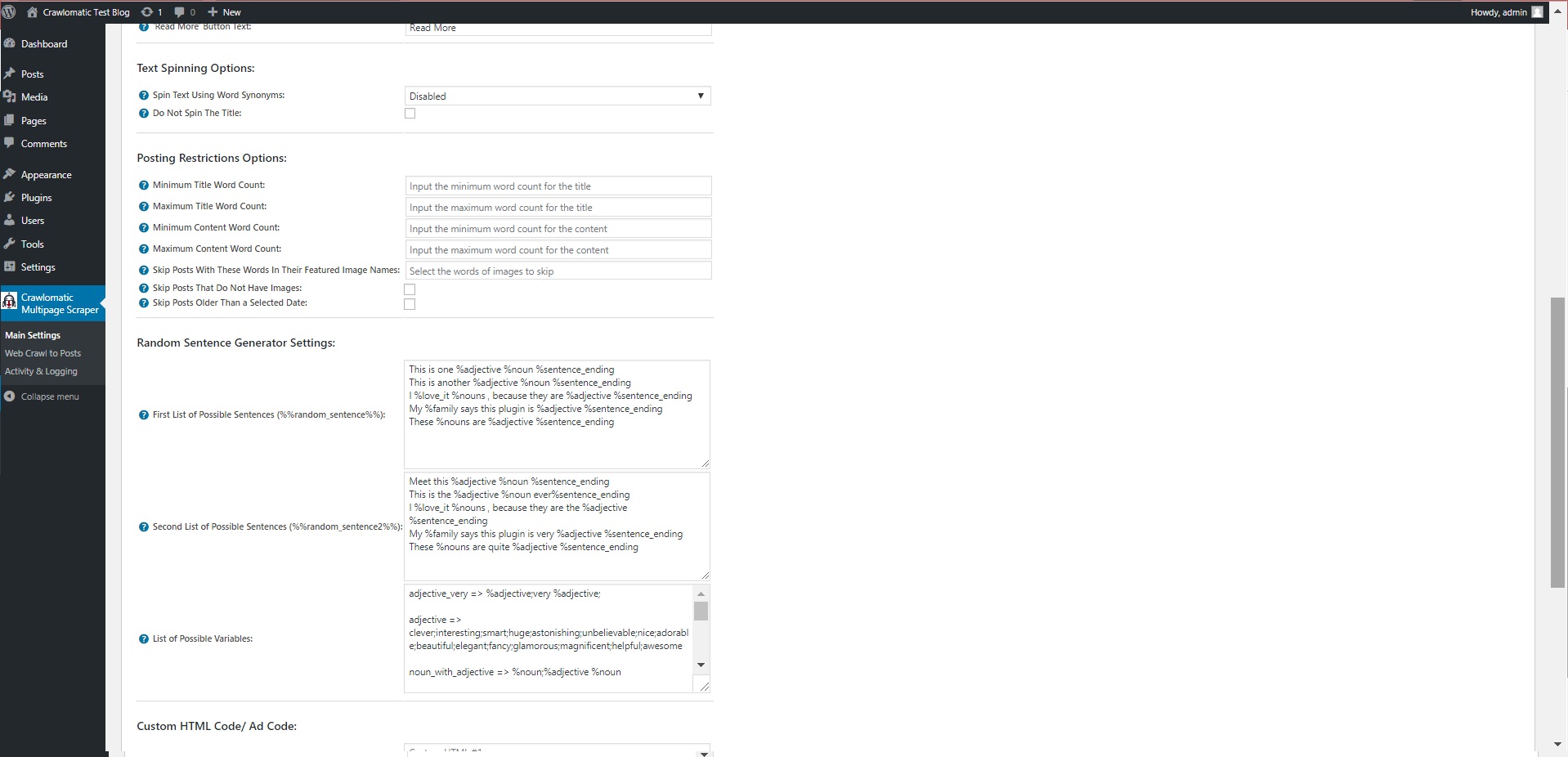
- Text Spinner support – automatically modify generated text, changing words with their synonyms – built-in, The Best Spinner, SpinRewriter, WordAI, TurkceSpin and others – great SEO value!
- customizable generated post status (published, draft, pending, private, trash)
- shortcode to list all posts generated by this plugin: [crawlomatic-list-posts type => ‘any’, order => ‘ASC’, ‘orderby’ => ‘date’, ‘posts’ => 50, ‘category’ => ’’, ‘ruleid’ => ’’]
- crawling and scraping can be set to respect the robots.txt files of websites and robots HTML headers of scraped pages
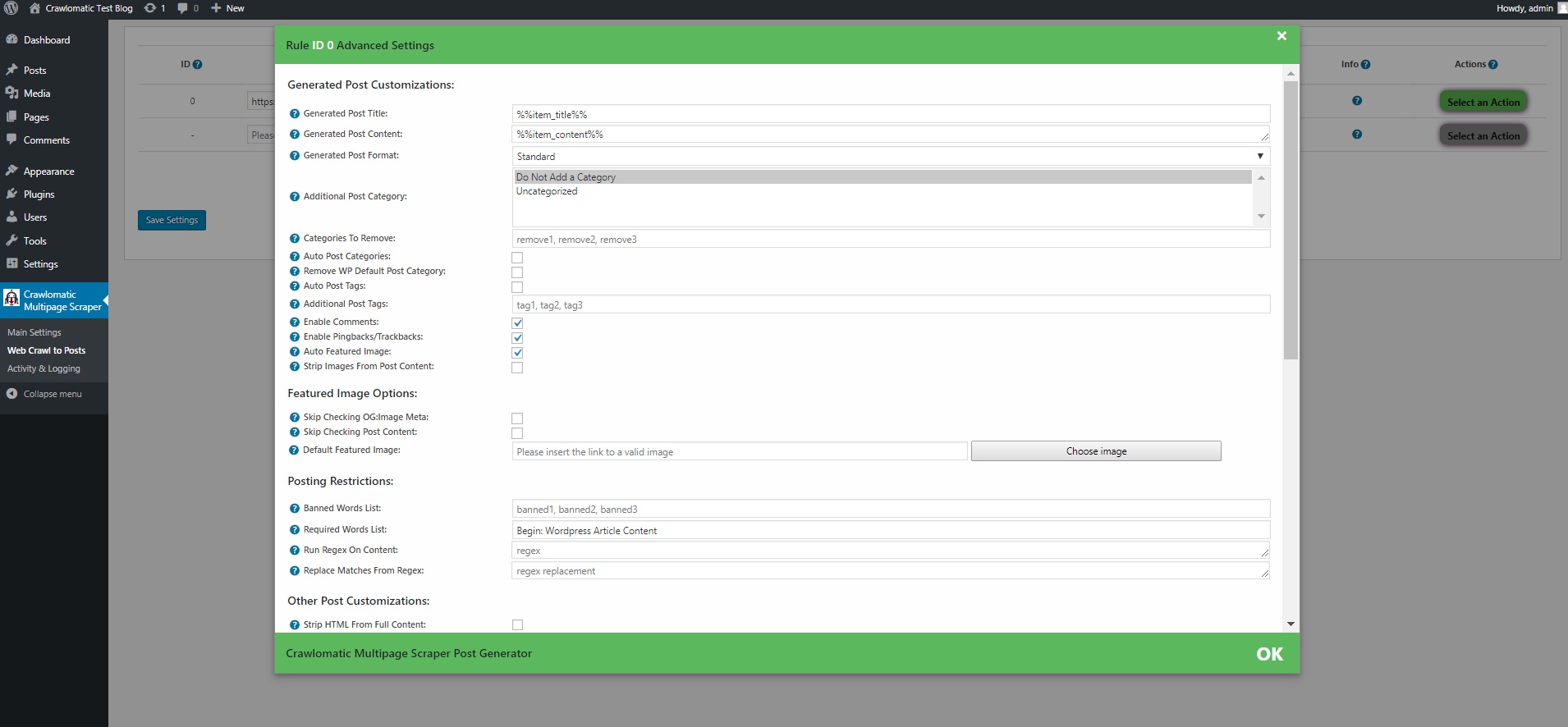
- automatically generate post categories or tags from marketplace items
- manually add post categories or tags to items
- choose if you want to update post if it is already posted
- send custom cookies with the request to the crawled webpage (authentification)
- generate post or page or any custom post type
- embeds videos from YouTube, Vimeo, Flickr, IGN, Ustream.tv and DailyMotion using website crawling and scraping
- define publishing constrains: do not publish posts that do not have images, posts with short/long title/content
- automatically generate a featured image for the post
- enable/disable comments, pingbacks or trackbacks for the generated post
- customize post title and content (with the included wide variety of relevant post shortcodes)
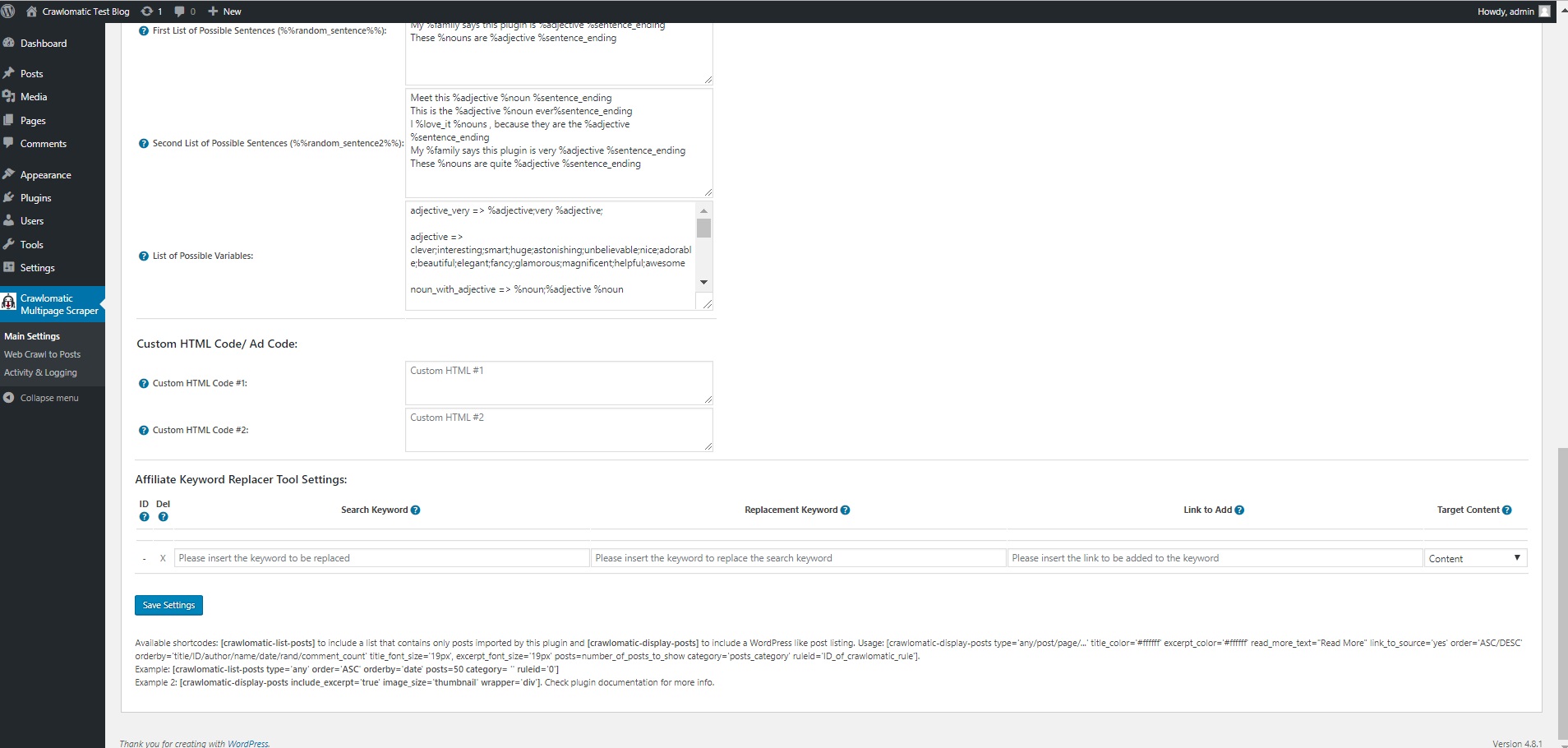
- ‘Keyword Replacer Tool’ – It’s purpose is to define keywords that are substituted automatically with your affiliate links, anywhere they appear in the content of your site. For example, you can define a keyword ‘codecanyon’ and have it substituted by a link to http://www.codecanyon.net/?ref=user_name anywhere it appears in your site’s content.
- ‘Random Sentence Generator Tool’ (relevant sentences – as you define them)
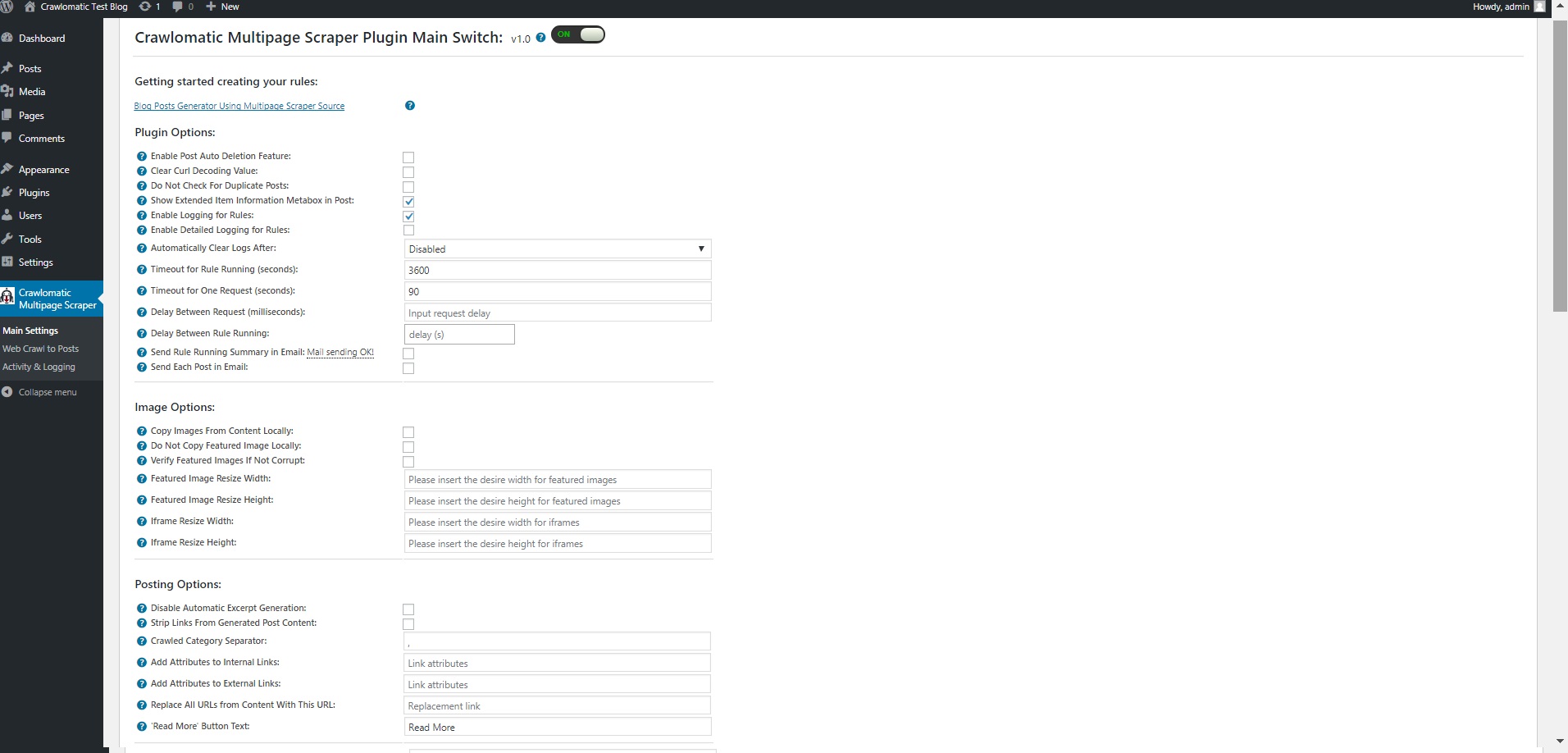
- option to automatically delete generated posts after a period of time
- detailed plugin activity logging
- scheduled rule runs
- custom field support for generated posts
- custom taxonomies support for generated posts
- unlimited crawled variable importing (unlimited imported parts of the crawled pages)
- option to copy or not images locally
- ability to parse JSON data using Regex
- option to add canonical meta tag to generated posts
- Maximum/minimum title length post limitation
- Maximum/minimum content length post limitation
- Add post only if predefined required keywords found in title/content
- Add post only if predefined banned keywords are not found in the title/content
- Save and restore plugin rule list from file
Testing this plugin
- You can test the plugin’s functionality using the ‘Test Site Generator’. Here you can try the plugin’s full functionality. Note that the generated testing blog will be deleted automatically after 24 hours.
Plugin Requirements
- PHP DOM -> how to install it (if you don’t have it, but probably you already have it): http://php.net/manual/en/dom.setup.php
- PHP 5.0 or higher
- dom, mbstring, iconv and json extensions (enabled by default)
For more info on how to configure the plugin, please check also this 1 hour long tutorial video, which covers the full feature set of the plugin.
Need support?
Please check our knowledge base, it may have the answer to your question or a solution for your issue. If not, just email me at support@coderevolution.ro and I will respond as soon as I can.Changelog:
Version 1.0 Release Date 2017-08-15First version released!Version 1.1 Release Date 2017-08-16
Fixed some small issuesVersion 1.2 Release Date 2017-08-17
Added the ability to crawl page by div class or idVersion 1.2.1 Release Date 2017-08-18
Fixed incompatibility with some WordPress installsVersion 1.2.2 Release Date 2017-08-22
Added a shortcode to display post generated by this pluginVersion 1.2.3 Release Date 2017-08-30
Added an option to crawl the page from Google cache when direct crawling fails (blocked)Version 1.2.4 Release Date 2017-08-31
Added the ability to set proxies for crawling pagesVersion 1.2.5 Release Date 2017-09-04
Added the canonicalization for generated articlesVersion 1.2.6 Release Date 2017-09-13
Made the plugin timezone awareVersion 1.2.7 Release Date 2017-09-14
Fixed post date for non gmt blogsVersion 1.2.8 Release Date 2017-09-23
Added paginated post importing supportVersion 1.2.9 Release Date 2017-09-27
BugfixesVersion 1.3.0 Release Date 2017-09-28
Fixed rule restoreVersion 1.3.1 Release Date 2017-10-20
Fixed featured image generationVersion 1.3.2 Release Date 2017-10-22
Added crawling helperVersion 1.3.3 Release Date 2017-11-06
Fixed a memory issueVersion 1.3.4 Release Date 2017-11-07
BugfixesVersion 1.3.5 Release Date 2017-12-14
Fixed class selector not working in all casesVersion 1.3.6 Release Date 2017-12-18
Added the ability to specify a custom user agent for each crawled webpageVersion 1.3.7 Release Date 2018-01-20
Added a new text spinner service: SpinrewriterVersion 1.3.8 Release Date 2018-01-22
Plugin can now continuously import contentVersion 1.3.9 Release Date 2018-02-02
Fixed issue when multiple crawl classes where specifiedVersion 1.4.0 Release Date 2018-02-22
Major update: added the ability to crawl imported product prices (WooCommerce compatible) Added the ability to crawl serial content (paged crawling - crawling for articles will continue on the next page)Version 1.4.1 Release Date 2018-03-07
BugfixesVersion 1.4.2 Release Date 2018-03-21
Fixed a duplicate posting issueVersion 1.4.3 Release Date 2018-03-22
Fixed a critical issue with multiple rule runningVersion 1.4.4 Release Date 2018-04-04
Added the ability to define multiple proxies. The plugin will select one at random at each page accessVersion 1.4.5 Release Date 2018-07-13
Updated built-in readability moduleVersion 1.4.6 Release Date 2018-07-16
Critical bugfixesVersion 1.4.7 Release Date 2018-07-19
Added the ability to not translate linksVersion 1.4.8 Release Date 2018-09-05
Added JavaScript execution support for crawled pages - requires PhantomJS installed on serverVersion 1.4.9 Release Date 2018-09-18
BugfixesVersion 1.5.0 Release Date 2018-09-24
Added the ability to add custom post taxonomies from crawled content Added the ability to add unlimited crawled variables to posts's content/ meta/ taxonomiesVersion 1.5.1 Release Date 2018-10-16
Fixed issue when importing large pagesVersion 1.5.2 Release Date 2018-10-24
Added the ability to shorten linksVersion 1.5.3 Release Date 2018-10-29
Fixed issue when importing paginated postsVersion 1.5.4 Release Date 2018-11-06
Added the ability to strip HTML elements by tag name (div,a,span,etc.)Version 1.5.5 Release Date 2018-11-07
Added WooCommerce product category creation supportVersion 1.5.6 Release Date 2018-12-16
Added nested importing support - import mixed content into a single post, from multiple plugins created by CodeRevolutionVersion 1.5.7 Release Date 2018-12-16
Added the ability to define a list of URLs to skip from crawling and importingVersion 1.5.8 Release Date 2019-01-08
Added the ability to import royalty free images for created postsVersion 1.5.9 Release Date 2019-01-12
Added Gutenberg blocks supportVersion 1.6.0 Release Date 2019-02-01
Added the ability to make screenshots of scraped pagesVersion 1.6.1 Release Date 2019-02-06
Improved compatibility with some crawled pagesVersion 1.6.2 Release Date 2019-04-19
Security updateVersion 1.6.3 Release Date 2019-05-15
Fixed some recently found bugs with post paginationVersion 1.6.4 Release Date 2019-05-17
Added support for TurkceSpin content spinnerVersion 1.6.5 Release Date 2019-05-27
Added a much demanded new feature: Visual Content Selector for assigning scraped page content Added the ability to scrape pages from bottom to top Added the ability to replace words in scraped content Other minor bug fixes and functionality improvementsVersion 1.6.6 Release Date 2019-07-26
Fixed timeout issue with some crawled pages Many small issues fixed and features improvedVersion 1.6.7 Release Date 2019-08-05
Fixed issue with Google TranslateVersion 1.6.8 Release Date 2019-11-15
WordPress 5.3 compatibility updateVersion 1.6.9 Release Date 2020-05-11
New features added for content templates Bugfix updateVersion 1.7.0 Release Date 2020-07-21
Added support for scraping more sitesVersion 1.7.1 Release Date 2020-09-28
Added the ability to crawl sitemaps and to scrape posts linked in them Added the ability to respect the directives set in the robots.txt filesVersion 2.0.0 Release Date 2020-12-08
Added a new shortcode and Gutenberg block alternative that will enable live scraping of any website Major performance improvement Fixed reported bugsVersion 2.1.0 Release Date 2021-01-02
Added support for using the Tor Browser to crawl dark web sites! Scrape .onion websites like you would scrape any other public website!Version 2.1.1 Release Date 2021-01-04
Added the ability to crawl and scrape pages using POST requests (POST form submission scraping support)Version 2.2.0 Release Date 2021-01-14
Added support for HeadlessBrowserAPI to scrape JavaScript rendered content with easeVersion 2.2.1 Release Date 2021-01-16
PHP 8 compatibility update Added support for crawling links from RSS feedsVersion 2.2.2 Release Date 2021-01-28
Fixed rare issue when saving importing rule settings on some PHP 8 configurationsVersion 2.2.3 Release Date 2021-02-01
Improved content extraction algorithmVersion 2.2.4 Release Date 2021-02-17
Added the ability to not spin posts generated by specific rulesVersion 2.2.5 Release Date 2021-03-07
Added the ability to enter multiple URLs (one per line) to be crawled and scrapedVersion 2.2.6 Release Date 2021-03-07
Visual Selector improvements - now it will be able to use HeadlessBrowserAPI/Puppeteer/PhantomJS/Tor to visualize scrape contentVersion 2.2.7 Release Date 2021-04-02
Fixed rare issues when crawling links with URL parametersVersion 2.2.8 Release Date 2021-04-07
Fixed rare issues with relative URL paths in crawled contentVersion 2.2.9 Release Date 2021-05-03
Added the ability to skip publishing of new posts if not images found (separately, for each rule)Version 2.3.0 Release Date 2021-05-19
Added the ability to make screenshots of websites using the HeadlessBrowserAPI featureVersion 2.3.1 Release Date 2021-06-10
Fixed content extracting/stripping in case of some websites with dynamically generated contentVersion 2.3.2 Release Date 2021-07-15
Added multiple Regex expression support (for content stripping and replacement)Version 2.3.3 Release Date 2021-07-18
Added SpinnerChief to the supported premium text spinners (SpinRewriter, The Best Spinner, WordAI, TurkceSpin)Version 2.3.4 Release Date 2021-07-19
Added Bing Translator support (next to Google Translator and DeepL Translator)Version 2.3.5 Release Date 2021-08-06
Added the ability to execute your own custom JavaScript on scraped pages when using headless browsers (PhantomJS/Puppeteer/Tor) or HeadlessBrowserAPI (XSS - cross site scripting feature) and scrape the resulting HTML contentVersion 2.3.6 Release Date 2021-08-30
Added the ability to set featured images of posts from website screenshots Added the ability to remove HTML content (leave text only) of XPath matched contentVersion 2.3.7 Release Date 2021-09-02
Added the ability to set local storage objects when scraping websites (these are similar to cookies, their usage is supported only when using headless browsers or HeadlessBrowserAPI in conjunction with the plugin)Version 2.3.8 Release Date 2021-09-15
Added the ability to set the WPML language to created postsVersion 2.3.9 Release Date 2021-10-19
WooCommerce product scraping related improvementsVersion 2.4.0 Release Date 2022-02-28
Added support for creating WooCommerce product attributes and assign values to them from scraped dataVersion 2.4.1 Release Date 2022-03-05
Added the ability to scrape image galleries for WooCommerce productsVersion 2.4.1.1 Release Date 2022-03-21
Bugfix updateVersion 2.4.2 Release Date 2022-04-20
Fixed Google Translator problem caused by a recent Google API updateVersion 2.5.0 Release Date 2022-05-01
Crawlomatic now can scrape search engine results from Google and Bing - tutorial video: https://www.youtube.com/watch?v=h6fQeH9-X8cVersion 2.5.1 Release Date 2022-05-06
Added the ability to scrape WooCommerce product variations from Shopify and other WooCommerce products Added the ability to automatically detect product prices Improved readability module Fixes and improvementsVersion 2.5.2 Release Date 2022-06-14
Added the ability to translate posts a third time (acting like a Word Spinner, if the content is translated back to the original languageVersion 2.5.3 Release Date 2022-06-23
Fixed WooCommerce price scraping related issueVersion 2.5.4 Release Date 2022-09-12
Added the ability to scrape links from TXT filesVersion 2.5.5 Release Date 2022-10-14
Major update: post/page/product automatic updating if the scraped source URL changedVersion 2.5.6 Release Date 2022-11-30
Major update: added support for Google News scrapingVersion 2.5.7 Release Date 2023-01-05
Added a new ability to HeadlessBrowserAPI to click on HTML elements by CSS selectors, enabling loading of Ajax content and bypassing Captchas which require a clickVersion 2.5.8 Release Date 2023-01-17
Added product regular price scraping feature to WooCommerce products - the regular price is the price displayed before the discount is applied. You can scrape this full price from the websites or add/multiply the original price to create it automaticallyVersion 2.5.9 Release Date 2023-02-10
Fixed Google News scraping after recent changesVersion 2.6.0 Release Date 2023-03-13
Added more DeepL languages Multiline scraping expressions support added Fixed all reported issuesVersion 2.6.0.1 Release Date 2023-04-13
Fixed reported bugsVersion 2.6.0.2 Release Date 2023-05-10
Improved scraper auto detectionVersion 2.6.0.3 Release Date 2023-05-22
Fixed more reported bugsVersion 2.6.0.4 Release Date 2023-06-13
Reworked backend, improved scraping speedVersion 2.6.0.5 Release Date 2023-06-29
Scraped content now better matches source site stylingVersion 2.6.0.6 Release Date 2023-07-28
Fixed Google Translate integration, working with latest changesVersion 2.6.0.7 Release Date 2023-10-18
Fixed PHP 8.2 related errorsVersion 2.6.1 Release Date 2024-02-15
Fixed an issue with rule savingVersion 2.6.2 Release Date 2024-03-15
Visual selector fix for CSS issue happening in some casesVersion 2.6.3 Release Date 2024-07-12
Bugfix release Purchase code verification now required for the plugin to functionVersion 2.6.4 Release Date 2024-10-26
Content filtering improvementsVersion 2.6.5 Release Date 2024-10-31
Added support for automatic Magento product variation scrapingVersion 2.6.6 Release Date 2024-12-26
The plugin will detect if the same image was scraped before to the media library and will not scrape the same image twice, but will reuse the existing media library IDVersion 2.6.7 Release Date 2025-03-28
Fixed reported issuesVersion 2.6.8 Release Date 2025-04-25
Supports WooCommerce product variation scraping from Rank Math JSON data from productsVersion 2.6.8.1 Release Date 2025-05-07
Fixed reported security issueVersion 2.6.8.2 Release Date 2025-05-16
Fixed reported critical security issueVersion 2.6.9 Release Date 2025-06-03
Fixed another security issueVersion 2.7.0 Release Date 2025-11-17
Added the ability to convert created posts to Gutenberg blocksVersion 2.7.1 Release Date 2025-12-05
Added the ability to scrape web-stories (web-story scraper)Version 2.7.2 Release Date 2026-03-05
Added the ability to scrape JSON structures of API responses and extract links from themVersion 2.7.3 Release Date 2026-05-20
Security fix: removed unsafe shortcode callback execution from crawlomatic-scraper callback_raw/callback attributes. Updated user agents
Are you already a customer?
If you already bought this and you have tried it out, please contact me in the item’s comment section and give me feedback, so I can make it a better WordPress plugin!WordPress 7.0 and PHP 8.5 Tested!
Disclaimer
Through this plugin you are able to grab content from various websites that does not necessary belong to you or which are not under your control. If you grab copyrighted material without the author’s permission, the plugin’s developer does not assume any responsibility for your actions. Also, the plugin’s developer has no control over the nature, content and availability of those sites.
Do you like our work and want more of it?
Check out this MEGA plugin bundle.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}